About the project
How can policymakers hear what young people are concerned about? What can software look like that highlights unheard issues? Where is AI useful, where is it dangerous? Youth Amplifier explores these questions and has developed a prototype.
Based on various social media data, such as tweets or Instastories, topics of young and young adult users are to be sorted thematically. This first prototype works with Twitter data because it is the easiest to process. After a test phase, other platforms will be added.
The prototype ist structured in the following way: Young people send messages to bots or donate their timelines. Subsequently, structuring and anonymization of the incoming data takes place. After that, all incoming tweets are clustered into a selectable number of topics. This clustering is visualized at the end on jugendverstärker.digital.
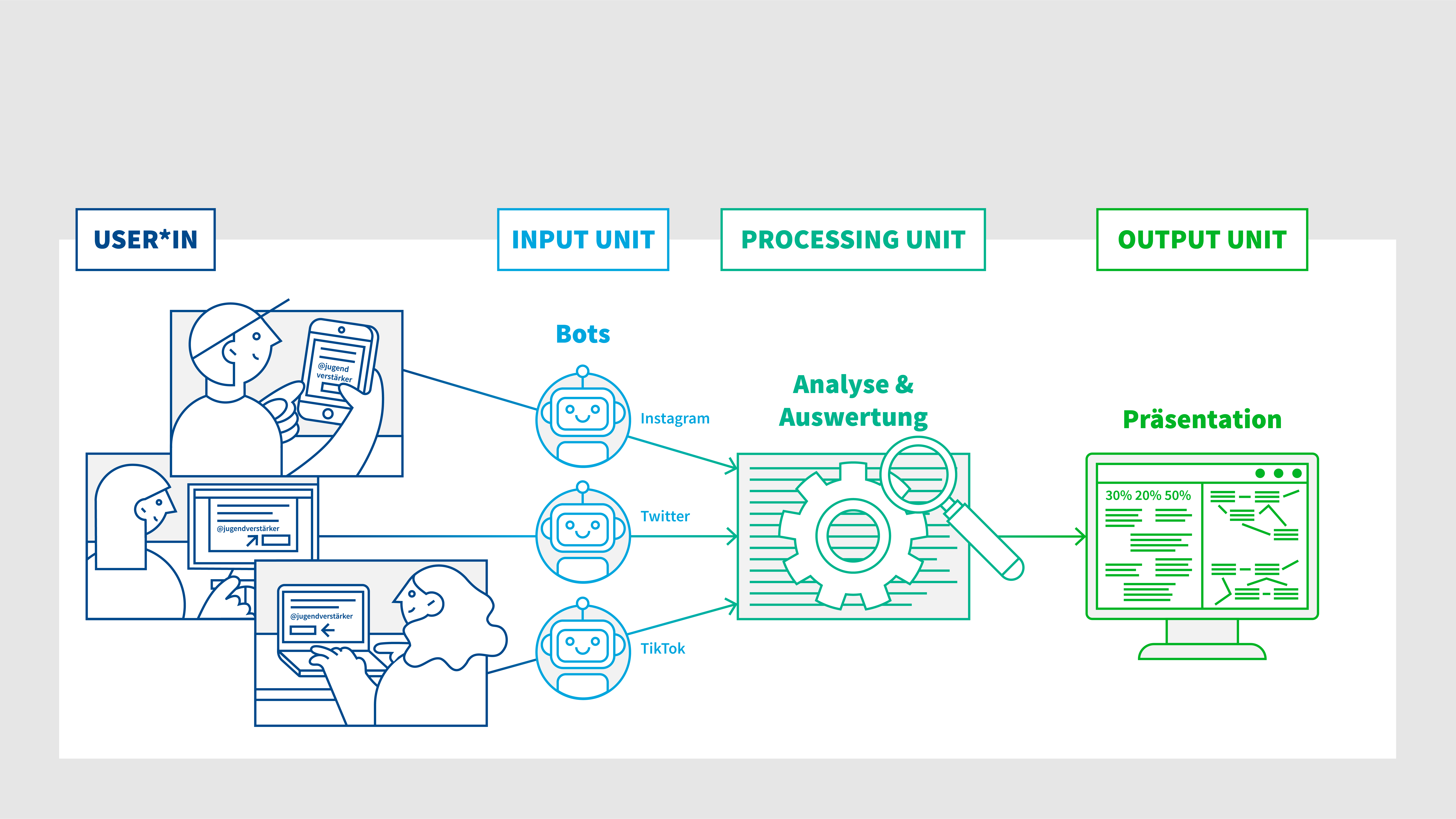
The prototype
The prototyp consists the following parts (red: planned, but not coded):
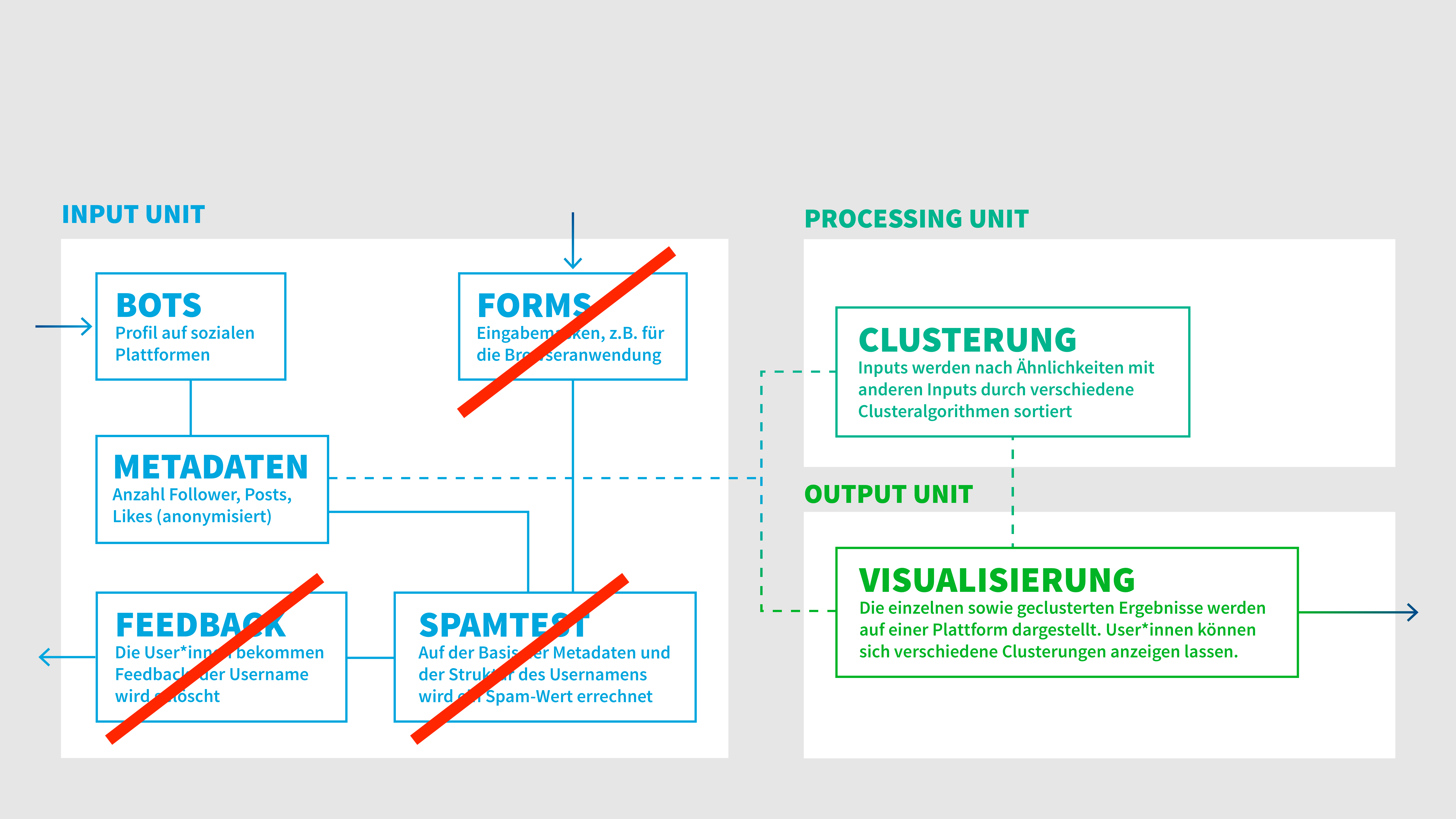
- input unit: backend behind the bot to collect Tweets.
- processing unit: Python API and scritps to collect the tweets, run the topic clustering methods and save the results.
- output unit: Vue 3 app to visualize (see https://jugendverstaerker.digital) the topics generated and interface to try clustering methods with different number of clusters.
Research documentation
Different approaches were tested for the selection of an appropriate clustering method. The documentation for this can be found here: Jupyter Notebooks testing the methods